Unproven Algorithms
Principled Teacher Selection for Knowledge Distillation
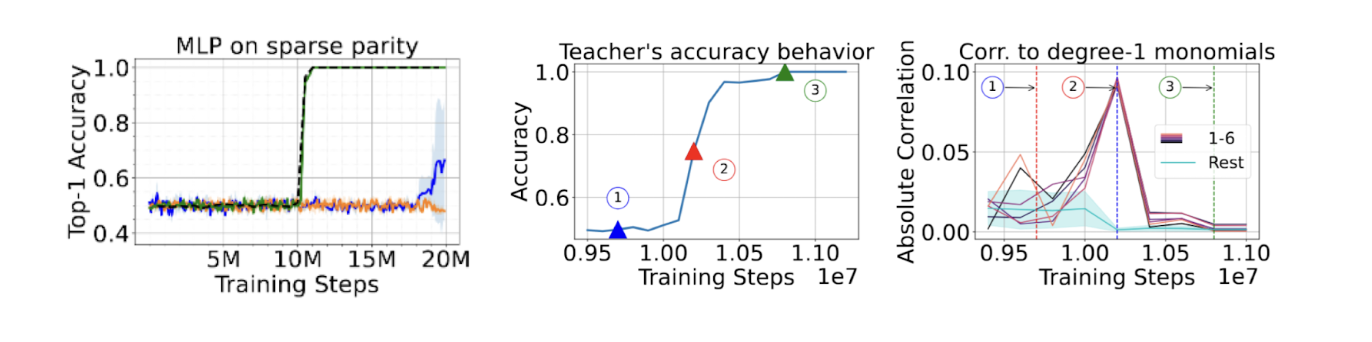
By Abhishek Panigrahi, Bingbin Liu, Sadhika Malladi, Sham Kakade and Surbhi Goel. TL; DR Training students on teacher-generated responses can significantly improve math reasoning in small models, but selecting the right teacher remains an open question. We introduce GRACE, a cost-efficient gradient-based score that ranks teachers without training the student. On MATH and GSM8K, GRACE achieves up to 86% correlation with the final student performance.... Read more 22 Dec 2025 - 9 minute read
How Progressive Distillation Unlocks Faster training in AI Models
By Abhishek Panigrahi, Bingbin Liu, Sadhika Malladi, Andrej Risteski and Surbhi Goel. TL; DR Progressive distillation, where the student model distills from several intermediate teachers, is shown to outperform distilling directly from the strongest teacher. Our work provides an explanation to progressive distillation’s effectiveness, from an optimization perspective. Intuitively, the intermediate teacher checkpoints provide an “implicit curriculum” of easier-to-learn subtasks, which eases the student’s optimization.... Read more 23 Apr 2025 - 12 minute read
The Evolution of Statistical Induction Heads
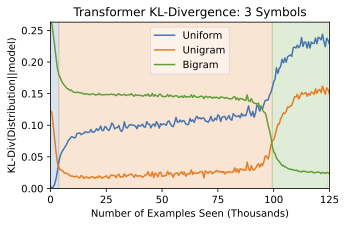
By Ben Edelman, Ezra Edelman, Surbhi Goel, Eran Malach, and Nikos Tsilivis. Machine learning works based on the inductive principle that patterns in the training data are likely to continue to hold. Large language models are induction machines—during training, they gobble up billions of words of text, extracting myriad patterns that can be used to predict the next token. But part of what makes... Read more 17 Feb 2024 - 12 minute read
What's in a name?

I bet you’re wondering how we came up with this amazing, creative, beautiful name. Well, the credit actually goes to Wilder in Philly. Given the fact that most of deep learning still remains unproven, we thought it suited the blog well. As an added bonus, the namesake drink tastes great too!
Read more 16 Feb 2024 - less than 1 minute read